Using technology to extract important data from documents is nothing new. On the contrary. For several decades now, various technological approaches have been used for exactly this purpose. But what all these different approaches had in common until relatively recently was that these systems were set up, configured, trained, and then operated locally at the customer’s premises. This has several obvious disadvantages. Already setting up such locally operated systems alone costs a lot of time and money. And even more important… Any quality improvements or expansions beyond the “standard” or the initial configuration of document types must be added and specifically developed in projects. This means that the more powerful your system should be, the more resources are required for developing it.

Global Learning Network
What we have now set out to do with Parashift is to overcome this very limiting infrastructure and build an open architecture that can be easily developed further instead. This will allow us to address the problems of document processing, especially extraction, with the help of a specifically designed global learning network. We create the basis for this with a strictly protected, highly available and freely scalable cloud platform. Through the cloud setup we offer you a universally available platform that can be easily integrated into your existing software landscapes and workflows. It is equipped with all existing functionalities from the beginning, but at the same time can be continuously upgraded with improved as well as new functionalities. And all this without your active involvement and of course without interrupting your productive operations.
This approach not only allows us to significantly shorten the ramp-up phase until you are able to switch to normal operations, but also to increase the variation of documents processed with each new customer. This is very crucial as our extraction platform makes use of various machine learning technologies in addition to classic OCR technologies (more on the difference between tradition OCR software and machine learning-based OCR). The reason for using this particular type of technology is simple: through swarm learning on all documents in the network, they help us to find correlations in large amounts of data points and then share these learnings with all customers, while the actual data, i.e. the sensitive document data, is strictly protected and not shared.
To ensure that the machine learning clusters are trained at all and that the resulting learnings actually improve the machine in the long term, we have set up specifically trained annotation and validation teams. These teams carry out efficiently designed post-processing of the classification and extraction results, so that on the one hand you as a customer can obtain viable extraction results at attractive prices and on the other hand the performance of the machine can be improved. This means that over time, less human interaction is required and the solution can be offered even more cost-effectively.
In concrete terms, this means that machine learning technologies aggregate context-based coherences in these post-processing processes with the support of humans, which help in the classification of the input, in this case the document type, and the subsequent extraction of the data relevant for this document type. Some of these correlations are obvious and totally logical and comprehensible for us humans. Others are not. And the more variations the machine has processed of a certain document type respectively the more of these documents have been validated by qualified human post-processing, the higher is the probability that completely new, never seen layouts and formats of the same type are recognized as such and that the machine knows from where it has to extract which data.
Standard document types
Our goal is therefore to work with our customers to configure individual document types step by step, which we can play out to all customers for use as so-called standard document types via our platform. If they then process their documents of the respective type with us, we will expand the document variation in our learning network and can increase the flexibility and robustness of our platform. In this initial phase of each new standard document type, however, it is important that we process as much as possible with customers using our full-extraction method so that the machine can be trained quickly and widely by our validation teams. This way, the necessary human validation can be reduced more quickly and the purely machine-based extraction performance can be improved.
The idea behind this is that it will enable us to develop such powerful technologies in the long term, which are not only functionally unbeatable, but also a total no brainer in economic terms. The exciting thing is that with the increasing validated document variety, further multiplication is stimulated as the quality and reliability of the extraction becomes better and better and as a result, more customers want to process their documents via Parashift. We are trying to use this monopoly-building dynamic for our and our customers’ benefit and thus build the global document extraction platform that will eventually be able to autonomously process any document uploaded within a few seconds and almost for free.
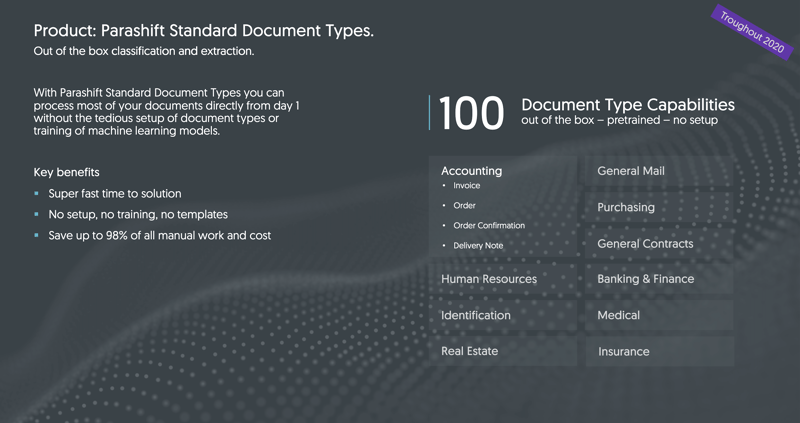
Roadmap for standard document types
When defining and planning new standard document types, we focus entirely on our customers and interested parties. The higher the overall demand for a specific document type, the higher we rate the relevance for its implementation. From previous discussions with customers and interested parties, the above illustrated collection of documents from various industries and sectors has therefore emerged, which we intend to release throughout 2020 and beyond. Should new customer relationships and requirements give rise to further interesting opportunities, the roadmap will be continuously updated accordingly.
Current standard Document types
Due to the increased needs of our customers for a certain range of particular document types, we have developed a Purchase to Pay Suite in a first step, which comes pre-configured and pre-trained with all common document types (i.e. offer, order, order confirmation, delivery note, pro-forma invoice, invoice/receipt, credit note and dunning). The Suite is going to be available at the beginning of April. So, after the easy integration of the platform via REST API you can start processing immediately and receive refreshingly fast and super cheap fully validated extraction results in your IT systems.
This, for example, enables the following use cases:
- Automatic entry of all the above mentioned document types
- Automatic invoice reconciliation against order data or contracts either for the total amount or in detail for the individual line items
- Shadow processing of invoices thanks to order comparison and all data for full booking data or suggestions
If you would like to learn more about this or if you would like to discuss your use case with us directly, let’s talk in the next few days. We will be happy to help you develop a suitable solution.
