Since computers have become established and documents have gradually become more and more needed in digital form, the way in which they can be converted has changed a lot. Fortunately… I say fortunately because the work of document capture per se is not really a fulfilling activity for the vast majority of people. But also because of the substantial costs that must be taken into account for these processes, which do not directly add any value but are yet very essential.
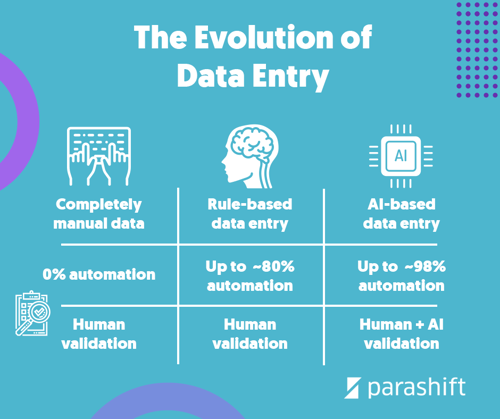
In the beginning, in finance and accounts payable departments, documents such as invoices were captured completely by hand by clerks and entered into some IT system. In the 70s, the first commercial solutions for automated text recognition (Optical Character Recognition abbreviation OCR) on various document types came to market (in the near future, I will write a separate blog article in which I will go into the OCR history in more detail). With these technologies certain steps in the document processing process could now be automated. A quantum leap.
This automated text recognition generated a computer searchable text from an image, similar to what we are used to from PDFs today. This already helps with the data entry, but does not automate it at all. What it did not solve either was the automated extraction of the most relevant data instead of the complete text.
Template-based OCR
That’s where template-based systems come into play. These allow the machine to be taught to isolate a certain section of text at a certain position in the text, behind a certain word or at a certain place, and to read it in a dedicated manner. For each field, you want to extract (e.g. a document number, date or address) you have to create a separate configuration and teach the computer where to find that field on the document. Worse still, these configurations only work as long as the document itself does not change. If the document structure deviates from the template, additional configurations are necessary. As a result of this lack of flexibility for variation, false positive results can occur from time to time.
Below is an example that illustrates this inflexibility. In this illustration, we have four different invoice documents for which we assume, for reasons of simplicity, that the position of the section shown on the invoice is the same in each case. The OCR is configured identically for all four invoices. It should search for the anchor point “Total” on all documents in the same region (in this case, the OCR software orients itself from top left to bottom right), then read the data to the right of this anchor point without including “CHF”.
In the first invoice, the wrong total is read out and the actual final amount, here marked as “Rechnungsbetrag inkl. MwSt”, is neglected. In the third invoice, we have the problem that the amount is in Euro instead of CHF, which means that not only the figure but also the Euro sign is extracted. Here you have to use a RegEx to cut off the Euro-sign. Since the fourth invoice has no “Total” anchor point at all, nothing is read out there. Only the second invoice is actually read out as we actually want it to be.

As you can see, the dependence on professionals for the fine-tuning of OCR is quite high and can be costly. Taking vendor invoices as an example, you can quickly imagine the effort these systems can already produce for a small business. Even these often have to deal with dozens of different suppliers, whereby each supplier usually structures his invoice slightly differently, which means that a separate template has to be created for each of these suppliers. In return for this massive effort, however, the extraction results for static documents are very good, which in this use case allows you to automate a large part of the previously manual work.
A successful scaling of the OCR application can therefore be extremely resource-intensive and also represents a major challenge for the active management of the required templates. Specifically, in addition to the initial cost of the technology, you must expect additional costs for maintenance, support, consulting and configuration. Since such adaptation projects also require internal planning and coordination, there are also internal costs on top of that.
Machine Learning-based OCR
One way to address the problems mentioned above is by using machine learning-based OCR solutions. Combine these with advanced software such as a Robotic Process Automation (RPA) software, a Business Process Management (BPM) tool, or your ERP system, and you can optimize your processes step by step, transforming the way your department or processing center works. What you get is more flexibility as well as more tangible things like faster processing times, less coordination effort for employees and therefore cost advantages.
But why is this approach so much more economical besides other things? This is mainly due to the fundamentally different design of such solutions. Instead of the OCR software having to be adjusted to a specific number of document templates for each company, different system components can be trained on text blocks of all sorts of different document layouts, regardless of format or naming, and, if it is a cloud OCR solution, its functionalities are directly shared with all software users (here you can find an article comparing cloud and on-premise OCR solutions). This aggregated document intelligence, therefore, eliminates much of the work involved in setting up and optimizing the software. This alone results in significant cost reductions. In addition, various machine learning technologies are becoming increasingly autonomous in the learning process and can come up with the rules necessary for qualitative extraction results themselves, which in turn relieves the experts in the configuration of the technologies. Also for annotation, approaches such as self-supervised learning may require less and less human interaction in the future.
Then we have complementary Natural Language Processing (NLP) technologies, that we can also incorporate and which provide the machine with an additional dimension that helps it to classify documents by word and text comprehension and extract the relevant data with higher quality. The models of the different document and field types developed with these various modalities thus generate more and more contextual knowledge about the nature of documents and their individual components via the increasing volume of documents processed, which ultimately promotes autonomy and can massively reduce the need for validation and, accordingly, costs.
What this means for you as a customer de facto is that you have a document processing software that can be implemented much faster, does not necessarily require projects with external specialists for expansion and quality improvement, which makes the whole thing much cheaper, leads to reduced processing times and offers much greater flexibility with regards to document input.
