Seit sich Computer etabliert haben und Dokumente sukzessive auch mehr in digitaler Form benötigt wurden, hat sich die Art und Weise, wie diese konvertiert werden können, glücklicherweise stark verändert. Glücklicherweise sage ich, da die damit verbundene Arbeit der Dokumentenerfassung per se für die allermeisten Menschen nicht wirklich eine erfüllende Tätigkeit ist. Doch auch aufgrund der substanziellen Kosten, die für diese nicht unmittelbar wertschöpfenden aber essenziellen Prozesse einkalkuliert werden müssen.
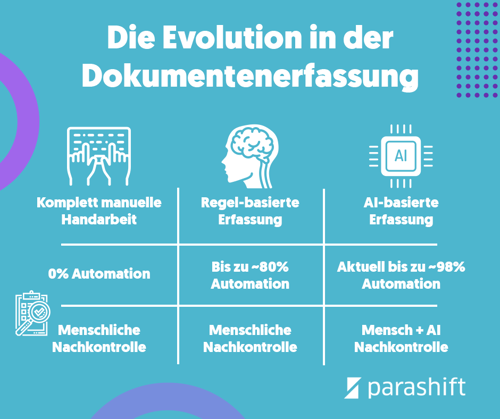
Während zu Beginn Dokumente wie beispielsweise Rechnungen in Finanz- und Kreditorenabteilungen von Sachbearbeitern komplett von Hand in irgendeinem IT-System erfasst wurden, kamen ab den 70ern die ersten kommerziellen Lösungen für die automatisierte Texterkennung (Optical Character Recognition Abk. OCR) auf verschiedensten Dokumenttypen auf den Markt (in naher Zukunft werde ich noch einen separaten Blogartikel verfassen, in dem ich vertiefter auf die OCR Geschichte eingehe). Durch diese Technologien konnten neu gewisse Schritte im Prozess der Dokumentenverarbeitung automatisiert werden. Ein Quantensprung.
Diese automatisierte Texterkennung generierte aus einem Bild einen durch Computer durchsuchbaren Text, ähnlich wie man es heute von PDFs gewohnt ist. Dies hilft bei der Eingabe bereits, automatisiert diese aber keinesfalls. Was damit auch nicht gelöst war, ist die automatisierte Extraktion der relevantesten Daten anstelle des kompletten Textes.
Template-basierte OCR
Hier kamen nun verstärkt Template-basierte Systeme, also Vorlagen-basierte Systeme, auf den Markt, die es erlaubten, der Maschine beizubringen, an einer bestimmten Stelle im Text, hinter einem bestimmten Wort oder an einer bestimmten Position, einen bestimmten Textabschnitt zu isolieren und dediziert auszugeben. Für jedes Feld, das man extrahieren wollte (z.B. eine Belegnummer, ein Datum oder eine Adresse) musste eine eigene Konfiguration angelegt und dem Computer beigebracht werden, wo er dieses Feld auf dem Dokument finden kann. Schlimmer noch: Diese Konfigurationen funktionierten natürlich nur so lange, wie sich das Dokument selbst nicht verändert. Weicht die Dokumentenstruktur von der Vorlage ab, sind zusätzliche Konfigurationen notwendig. Infolge dieser nicht vorhandenen Flexibilität für Variation kann es ausserdem immer wieder zu False Positive Resultaten kommen.
Nachstehend habe ich Ihnen ein Beispiel, das diese Inflexibilität verdeutlichen soll. In dieser Veranschaulichung haben wir vier verschiedene Rechnungsdokumente, für welche wir aus Simplizitätsgründen einmal annehmen, dass die Position des abgebildeten Ausschnittes auf der Rechnung jeweils die selbe ist. Die OCR ist für alle vier Rechnungen identisch konfiguriert. Diese soll auf allen Dokumenten in der selben Region nach dem Ankerpunkt “Total” suchen (die OCR Software orientiert sich in diesem Fall von oben links gegen unten rechts), dann die Daten rechts von diesem Ankerpunkt auslesen, ohne dass dabei “CHF” mit einbezogen wird.
In der ersten Rechnung wird das falsche Total ausgelesen und der eigentliche Endbetrag, hier als “Rechnungsbetrag inkl. MwSt” gekennzeichnet, vernachlässigt. Bei der dritten Rechnung haben wir das Problem, dass der Betrag in Euro statt CHF ist, womit nicht nur die Zahl, sondern auch das Euro-Zeichen extrahiert wird. Hier müsst eine RegEx eingesetzt werden, damit das Euro-Zeichen noch abgeschnitten wird. Da die vierte Rechnung gar keinen “Total” Ankerpunkt aufweist, wird dort gar nichts ausgelesen. Es wird also lediglich die zweite Rechnung tatsächlich so ausgelesen, wie wir das eigentlich wollen.

Sie sehen, die Abhängigkeit von Fachleuten für den Feinschliff der OCR ist recht gross und kann kostspielig werden. Am Beispiel von Kreditorenrechnungen kann man sich schnell den Aufwand vorstellen, den diese Systeme bereits für ein kleines Unternehmen produzieren können. Denn schon diese haben oft mit duzenden von verschiedenen Lieferanten zu tun, wobei in der Regel jeder Lieferant seine Rechnung etwas anders strukturiert, was bedeutet, dass für jeden dieser Lieferanten eine eigene Vorlage angelegt werden muss. Im Gegenzug für diese massiven Aufwendungen sind aber die Extraktionsergebnisse für statische Dokumente sehr gut, was Ihnen in diesem Anwendungsfall ermöglicht, einen Grossteil der zuvor manuellen Arbeit zu automatisieren.
Eine erfolgreiche Skalierung des OCR-Einsatzes kann also äussert ressourcenintensiv sein und stellt zudem eine grosse Herausforderung für das aktive Management der benötigten Vorlagen dar. Konkret müssen Sie neben den Anschaffungskosten der Technologie mit weiteren Kosten für die Wartung, den Support, Beratungen und Konfigurationen rechnen. Da solche Anpassungsprojekte darüber hinaus interne Planung und Koordination brauchen, kommen entsprechend noch interne Kosten dazu.
Machine Learning-basierte OCR
Eine Möglichkeit die genannten Problematiken zu adressieren, ist mittels dem Einsatz von Machine Learning-basierten OCR-Lösungen. Kombinieren Sie diese mit weiterführender Software wie einer Robotic Process Automation (RPA) Software, einem Business Process Management (BPM) Tool, oder Ihrem ERP-System, können Sie Ihre Prozesse schrittweise optimieren und so die Arbeitsweise Ihrer Abteilung beziehungsweise Ihres Verarbeitungszentrums grundlegend transformieren. Was Sie dadurch erhalten, ist mehr Flexibilität sowie greifbarere Dinge wie schnellere Durchlaufzeiten, weniger Koordinationsaufwand für Mitarbeiter und dadurch eben Kostenvorteile.
Wieso ist nun aber dieser Ansatz unter anderem so wesentlich wirtschaftlicher? Das ist hauptsächlich auf die grundlegend andere Ausgestaltung solcher Lösungen zurückzuführen. Denn anstatt dass die OCR Software jeweils unternehmensspezifisch auf eine bestimmte Anzahl an Dokumentenvorlagen eingestellt werden muss, können verschiedene Systemkomponenten benutzerübergreifend auf Textblöcke von allerlei verschiedenen Dokumentenlayouts, unabhängig von Format beziehungsweise Namensgebung, trainiert und, insofern es sich um eine Cloud-OCR-Lösung handelt, deren Funktionalitäten unmittelbar mit allen Software-Benutzern geteilt werden (hier finden Sie einen Artikel, der Cloud und On-Premise OCR-Lösungen einander gegenüberstellt). Diese aggregierte Dokumentenintelligenz erübrigt daher weite Teile der Projektphasen zum Setup und der Optimierung der Software. Alleine das hat erhebliche Kostenreduktionen zur Folge. Dazu kommt, dass verschiedene Machine Learning Technologien im Prozess des Lernens zunehmend autonomer werden und die für qualitative Extraktionsresultate notwendigen Regeln selbst erarbeiten können, was wiederum die Fachleute in der Konfiguration der Technologien entlastet. Auch für die Annotation wird durch Ansätze wie Self-Supervised Learning womöglich künftig immer weniger menschliche Interaktion benötigt.
Dann haben wir ergänzend Natural Language Processing (NLP) Technologien, welche wir ebenfalls mit einbeziehen können und der Maschine eine zusätzlich Dimension liefert, die ihr hilft, Dokumente durch Wort- und Textverständnis zu klassifizieren und deren relevanten Daten mit höherer Qualität zu extrahieren. Die mit diesen diverse Modalitäten entwickelten Modelle der verschiedenen Dokument- und Feldarten generieren so über das steigende verarbeitete Dokumentenvolumen immer mehr Kontextwissen über die Natur von Dokumenten und deren einzelnen Bestandteile, was letztlich Autonomie fördert und den Bedarf für Nachkontrollen sowie dementsprechend auch Kosten massivst reduzieren kann.
Was das für Sie als Benutzer de facto bedeutet, ist, dass Sie eine Software für die Dokumentenverarbeitung haben, welche bedeutend schneller implementiert ist, zur Erweiterung und Verbesserung nicht zwangsläufig Projekte mit externen Spezialisten voraussetzt, was das Ganze deshalb stark verbilligt, zu reduzierten Durchlaufzeiten führt und eine wesentlich höhere Flexibilität in Bezug auf den Dokumenteninput aufweist.
