Der Einsatz von Technologie für die Extraktion wichtiger Daten aus Dokumenten ist nichts Neues. Im Gegenteil. Bereits seit mehreren Jahrzehnten werden verschiedene Technologieansätze zu genau diesem Zweck eingesetzt. Was aber bis vor relativ kurzer Zeit alle diese verschiedenen Ansätze gemeinsam hatten, war, dass diese Systeme lokal beim Kunden aufgesetzt, konfiguriert, trainiert und dann auch betrieben wurden. Das hat diverse offensichtliche Nachteile. Denn schon allein das Aufsetzen solcher lokal betriebenen Systemen kostet viel Zeit und Geld. Und noch wichtiger… Jegliche Qualitätsverbesserungen oder Erweiterungen abseits des “Standards” oder der initialen Konfiguration der Dokumentarten müssen zusätzlich und spezifisch in Projekten erarbeitet werden. Das heisst, je leistungsstärker Ihr System sein soll, desto mehr Ressourcen sind dazu notwendig.

Globales Learning Network
Was wir uns nun bei Parashift vorgenommen haben, ist eben genau an dieser stark limitierenden Infrastruktur anzusetzen und an Stelle davon eine offene einfach weiterentwickelbare Architektur aufzubauen. Diese wird es uns erlauben, die Problematik der Dokumentenverarbeitung, insbesondere der Extraktion, mit Hilfe eines global ausgelegten Learning Networks anzugehen. Die Basis dazu schaffen wir durch eine streng geschützte, hoch verfügbare und beliebig skalierbare Cloud-Plattform. Durch das Cloud-Setup bieten wir Ihnen eine universell verfügbare Plattform, die einfach in Ihre bestehende Softwarelandschaften und Workflows integriert werden kann und von Beginn weg mit allen vorhandenen Funktionalitäten ausgestattet ist, aber gleichzeitig auch kontinuierlich mit verbesserten sowie neuen Funktionalitäten aufgewertet wird. Und das alles auch ohne Ihr aktives Zutun und natürlich ohne Ihren produktiven Betrieb dabei zu unterbrechen.
Durch diesen Ansatz können wir also nicht nur etwa die Ramp-up-Phase bis zum Normalbetrieb signifikant verkürzen, sondern wir erhöhen auch die Variation der verarbeiteten Dokumenten mit jedem neuen Kunden. Dies ist daher so wichtig, da unsere Extraktionsplattform neben klassischen OCR Technologien hauptsächlich von diversen Machine Learning Technologien Gebrauch macht (mehr zum Unterschied zwischen traditionellen OCR Software und Machine Learning-basierter OCR). Der Grund für den Einsatz dieser Art von Technologien ist simpel: Durch das Swarm Learning auf allen Dokumenten im Netzwerk helfen sie uns, Korrelationen in grossen Mengen von Datenpunkten zu eruieren und diese Learnings dann mit allen Kunden zu teilen, wobei die eigentlichen Daten, sprich, die sensiblen Dokumentdaten, strengstens geschützt und nicht geteilt werden.
Damit die Machine Learning Cluster überhaupt trainiert werden und die daraus gezogenen Learnings die Maschine tatsächlich nachhaltig verbessern, haben wir spezifisch ausgebildete Teams zur Annotation beziehungsweise Validierung aufgebaut. Diese führen effizient gestaltete Nachbearbeitungsprozesse der Klassifikations- und Extraktionsergebnissen durch, sodass einerseits Sie als Kunde viable Extraktionsergebnisse zu attraktiven Preisen beziehen können und anderseits eben die Performance der Maschine verbessert werden kann. Dies damit sukzessive weniger menschliche Interaktion benötigt wird und die Lösung somit noch kostengünstiger angeboten werden kann.
Konkret bedeutet das, die Machine Learning Technologien aggregieren in diesen Nachbearbeitungsprozessen mit menschlicher Unterstützung kontextbasierte Zusammenhänge, die bei der Klassifikation des Inputs, in diesem Fall der Dokumentart, und der darauffolgenden Extraktion der bei diesem Dokumenttypen relevanten Daten helfen. Gewisse dieser Zusammenhänge sind offensichtlich und für uns Menschen total logisch und nachvollziehbar. Andere wiederum sind dies nicht. Und je mehr Variation die Maschine von einer bestimmten Dokumentart verarbeitet hat beziehungsweise je mehr dieser Dokumente jeweils durch qualifizierte menschliche Nachbearbeitung validiert wurden, desto höher ist die Wahrscheinlichkeit, dass komplett neue, in dieser Art noch nie gesehenen Layouts und Formate vor selben Art, doch als solche erkannt werden und dann die Maschine auch weiss, von wo welche Daten zu extrahieren sind.
Standard Dokumenttypen
Ziel von uns ist es demnach, in Zusammenarbeit mit unseren Kunden schrittweise einzelne Dokumentarten zu konfigurieren, die wir als sogenannte Standard Dokumenttypen über unsere Plattform an alle Kunden zur Verwendung ausspielen können. Verarbeiten diese dann Ihre Dokumente des jeweiligen Typs mit uns, bauen wir die Dokumentenvariation in unserem Learning Network aus und können die Flexibilität und Robustheit unserer Plattform steigern. Wichtig in dieser initialen Phase eines jeden neuen Standard Dokumenttyps ist jedoch jeweils, dass wir mit Kunden möglichst viel über unsere Full-Extraction prozessieren, damit die Maschine schnell und in breiter Masse von unseren Validierungs-Teams trainiert werden kann. Somit können die notwendigen menschlichen Nachkontrollen schneller reduziert und die rein maschinenbasierte Extraktionsperformance gesteigert werden.
Die Idee dahinter ist, dass wir dadurch langfristig derart leistungsstarke Technologien entwickeln können, die nicht nur funktional unschlagbar, sondern auch wirtschaftlich gesehen ein totaler No Brainer sind. Spannend ist dabei, dass mit zunehmender validierten Dokumentenvarietät eine weitere Verfielfachung stimuliert wird, da die Qualität und Verlässlichkeit der Extraktion immer besser wird und aufgrund dessen mehr Kunden ihre Dokumente über Parashift verarbeiten wollen. Diese Monopol bildende Dynamik versuchen wir zu unseren beziehungsweise den Gunsten unserer Kunden zu nutzen und so die eine globale Plattform zur Dokumentenextraktion zu bauen, die irgendwann tatsächlich im Stande sein wird, ein beliebiges Dokument, das hochgeladen wird, innert wenigen Sekunden und fast kostenlos autonom zu verarbeiten.
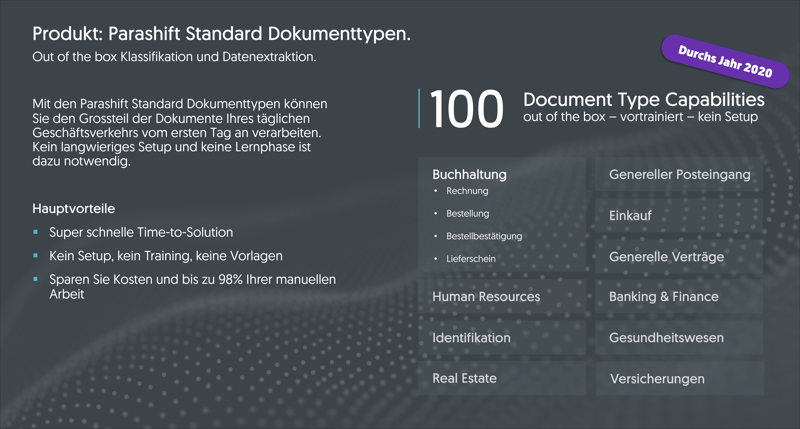
Roadmap für Standard Dokumententypen
Bei der Definition und der Planung neuer Standard Dokumenttypen richten wir uns voll und ganz nach unseren Kunden und Interessenten. Je höher die gesamte Nachfrage für eine bestimmte Dokumentenart, desto höher stufen wir die Relevanz für deren Umsetzung ein. Aus den bisherigen Gesprächen mit Kunden und Interessenten hat sich daher die oben illustrierte Ansammlung von Dokumenten aus diversen Branchen und Bereichen ergeben, die wir durchs Jahr 2020 und darüber hinaus live schalten wollen. Sollten sich aufgrund neuer Kundenbeziehungen und Requirements weitere interessante Opportunitäten anbieten, wird die Roadmap fortlaufend entsprechend ergänzt.
Aktuelle Standard Dokumententypen
Aufgrund der vermehrten Bedürfnisse unserer Kunden haben wir in einem ersten Schritt eine Purchase to Pay Suite entwickelt, welche ab anfangs April mit allen gängigen Dokumentarten (d.h. Angebot, Bestellung, Auftragsbestätigung, Lieferschein, Pro-Forma Rechnung, Rechnung/Quittung, Gutschrift und Mahnung) vorkonfiguriert und vortrainiert kommt. Nach der einfachen Integration der via REST API können Sie daher direkt mit der Verarbeitung loslegen und erhalten erfrischend schnell und super günstig voll validierte Extraktionsergebnisse in Ihre jeweiligen IT Systeme.
Damit ergeben sich exemplarisch die folgenden Use Cases:
- Automatische Erfassung der oben aufgezählten Dokumentarten
- Automatischer Rechnungsabgleich gegen Bestelldaten oder Verträge entweder auf Gesamtbetrag oder auch detailliert auf die Einzelpositionen
- Dunkelverbuchung von Rechnungen dank Bestellabgleich und allen Daten für vollumfassende Buchungsdaten beziehungsweise Vorschläge
Wenn Sie mehr darüber erfahren wollen oder Sie direkt Ihren Use Case mit uns besprechen wollen, lassen Sie uns doch in den kommenden Tagen einmal sprechen. Thilo Rossa, Head Business Development, hilft Ihnen gerne bei der Entwicklung einer passenden Lösung.
