In diesem Blogartikel will ich Ihnen näher bringen, was Parashift aktuell ist, was die Lösung zur Dokumentenextraktion ermöglicht und wie sie integriert werden kann. Zu guter Letzt gehe ich auch noch auf die Preise ein.
Was kann Parashift für Ihren Procure to Pay Prozess tun?
Mit Parashift bieten wir Ihnen eine Extraktionslösung, welche zur Klassifikation und Datenextraktion von über neun verschiedenen Procure to Pay Dokumentarten wie Angebote, Bestellungen, Lieferscheine, Rechnungen, etc. befähigt. Die daraus extrahierten Daten, spielen wir an Ihre nachgelagerten Prozesse in beispielsweise Ihrem ERP-System aus.
Im Vergleich zu anderen Lösungen am Markt klassifizieren wir nicht nur die unterschiedlichen Dokumente und lesen auf Basis dieser Klassifikation die relevantesten Felder wie beispielsweise den Lieferanten, Empfänger, Dokumentdatum und -nummer, Beträge inklusive Teilbeträge, Steuer und Steuersatz sowie Positionsdaten aus, sondern wir übernehmen auch gleich die komplette Nachkontrolle und Nachbesserung, der von der Maschine erkannten Werte. Damit garantieren wir Ihnen höchste Qualität, befreien Sie von lästiger und kostspieliger Abtipp-Arbeit und ermöglichen eine höhere Robustheit der Prozessautomationen, welche auf dem initialen Dokumenteninput aufbauen.
Bevor ich Ihnen die Plattform zeige, hier ein Überblick zur Verdeutlichung dessen, was wir wir im Hintergrund tun.
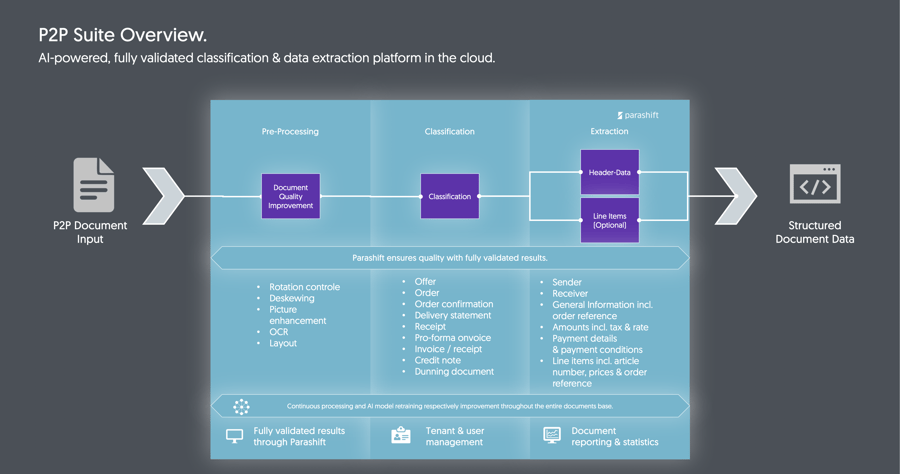
Dokumente werden im Normalbetrieb von Ihnen über ein REST API an die Plattform gesendet, wo wir eine Qualitätsverbesserung durchführen. Das heisst, wir nehmen beispielsweise eine Rotation vor, sollte das Dokument auf dem Kopf stehen, wir verbessern wenn notwendig die Qualität des Bildes und führen natürlich eine OCR sowie ein Layoutbildung aus. Anschliessend folgt die Klassifikation, wo wir identifizieren, um welche Dokumentart es sich handelt. Zuletzt extrahieren wir die wichtigsten Daten, um aus den unstrukturierten Dokumenten ein einheitliches, strukturiertes Datenformat zu erstellen, das an die nachgelagerten Systeme übergeben werden kann.
Neben den Kopfdaten wie Adresse des Lieferanten und Empfängers, Referenznummern, Lieferdaten, Totalbeträge inkl. Steuersätze und Zahlungsverbindungen extrahieren wir auch, insofern gewünscht, die einzelnen Positionsdaten mit allen relevanten Daten wie Artikelbeschreibung, Artikelnummer, Menge, Einzelpreis als natürlich auch Referenzen der Positionen zu Bestellungen und Lieferscheinen, welche bei Sammelrechnungen und Bestellabgleichen essenziell sind. Am Ende erhalten Sie via unsere einfach anzubindende REST API ein strukturiertes JSON-File zurück. Der ganze Prozess inklusive Kontrolle dauert dabei an Werktagen zwischen 08:00 und 17:00 Uhr maximal drei Stunden.
Die Vorteile der Lösung
Ergänzend zur Nachbearbeitung, die wir für Sie übernehmen, bieten wir ausserdem
- eine Lösung, die out-of-the-box funktioniert, ohne Setup- und Konfigurationsarbeiten und vor allem ohne initiales Trainingsprojekt
- eine schnelle & einfache Anbindung mittels unserer REST API und optional Webhooks an Ihr ERP-, Dokumentenmanagement-, Workflow-, ECM-System oder sonstige Business Software
- ein transparentes transaktionsbasiertes Pricing – neben den Kosten für die Verarbeitung Ihrer Dokumente gibt es keine weiteren Kosten. Mit uns sparen Sie sich also auch hohe Anschaffungskosten sowie sämtliche Server, Wartungs- oder Supportkosten
- sprich, durch unser Cloud-Setup sichern Sie sich top-notch OCR Software zu minimalen Preisen. Und das eben sogar inklusive Nachbearbeitung der Extraktionsergebnisse.
Kurzer Einblick in die Oberfläche
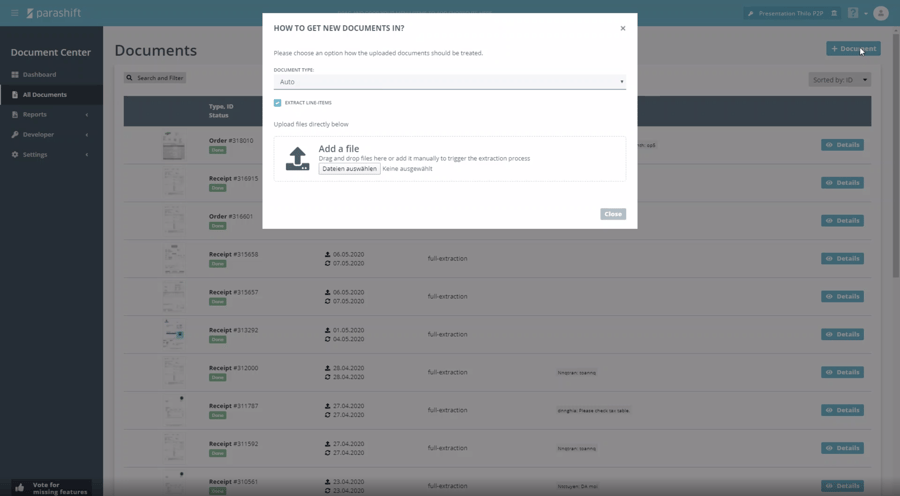
Schauen wir uns nun die grafische Oberfläche an, welche Sie aber im Normalbetrieb nicht benötigen werden. Dokumente können Sie hier, insbesondere wenn Sie nachher einen Testlauf starten, über den Button oben rechts im Bild hochladen. Beim Upload über den Dialog, welchen Sie hier im Screenshot als Pop sehen können, kann ich, wie bei dem Upload über unsere REST Schnittstelle, angeben ob Positionsdaten extrahiert werden sollen und ob das Dokument zu klassifizieren ist oder ich bereits eine fixe Dokumentart mitgeben will. Anschliessend gehen Dokumente in die Verarbeitung.
Wie schon erwähnt, spielen wir nach spätestens drei Stunden die voll kontrollierten und vervollständigten Extraktionsergebnisse zurück. Im Hintergrund geht unser System über das Dokument und interpretiert anhand aller durch uns jemals verarbeiteten Dokumente mittels Machine Learning die relevanten Daten, welche es zu extrahieren gilt.
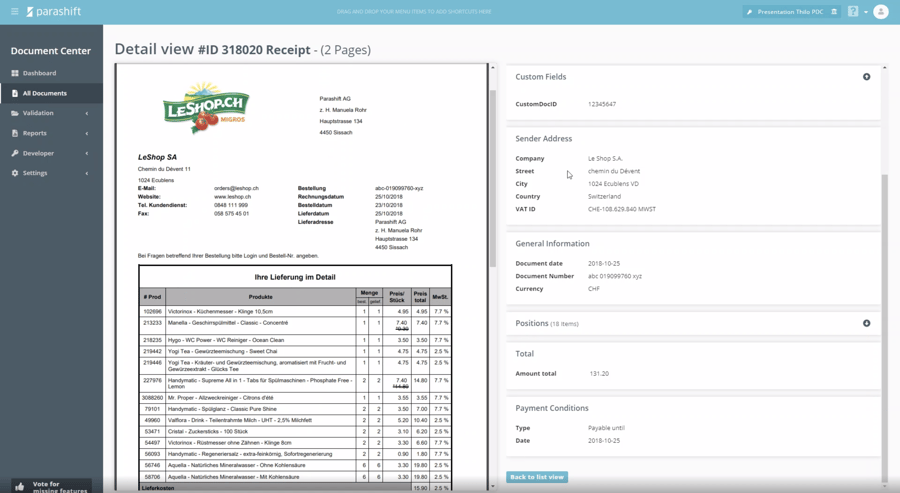
In diesem Beispiel sehen wir, dass der Lieferant erkannt wurde sowie auch diverse weitere Kopfdaten: Rechnungsdatum, Rechnungsnummer, Währung, Positionen als auch das Total und die Zahlungskonditionen. Nun ist es aber so, dass sich hier Fehler eingeschlichen haben können und sich die Maschine bei gewissen Feldern nicht sicher war, ob sie ihren Job richtig gemacht hat. Denn keine Maschine ist heute im Stande, eine makellose Performance über alle Dokumente hinweg hinzulegen. Zumindest noch nicht.
Durch unseren Ansatz Machine Learning methodisch neu und in einem nie zuvor erreichten Umfang auf Dokumenten anzuwenden und so von einem Swarm Learning Effekt zu profitieren, kommen wir unserer Vision, der autonomen Dokumentverarbeitung, das heisst perfekte Ergebnisse ohne menschliche Interaktion, mit grossen Schritten näher. Wir sind daher überzeugt, dass wir über die Zeit mehr und mehr menschliche Arbeit aus dem Prozess heraus nehmen und diese Kostenersparnis an Sie weiter geben können.
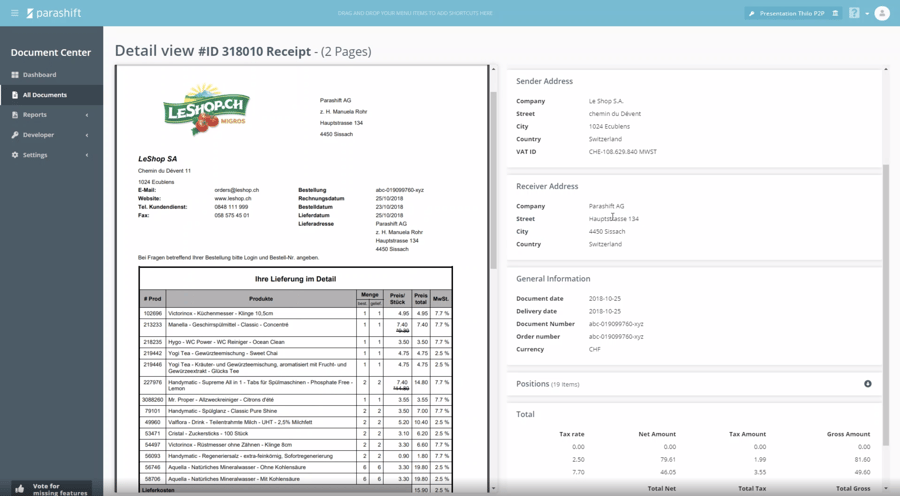
Die nachbearbeitete Version des hochgeladenen Dokumentes habe ich Ihnen hier auch einmal aufgeführt. Das wäre nun also die Art von Datenqualität, welche Sie von uns erwarten können. Wir haben hier anders als vorher auch den Rechnungsempfänger, der nicht extrahiert wurde. Das Leistungsdatum wurde ebenso ergänzt. Die Positionsdaten sind detaillierter nachgetragen worden sowie auch die Aufteilung des Totalbetrags nach den verschiedenen Steuersätzen und Netto- und Bruttobeträgen.
Basierend auf diesen Metadaten sollten Sie also im Stande sein, die Rechnung grösstenteils vollautomatisch durchbuchen zu können. Alternativ mit den Positionsdaten ermöglichen Ihnen die Daten auch die Rechnung direkt gegen Ihre interne Bestellung abzugleichen und zu kontrollieren, ob der Lieferant auch wirklich zu den Konditionen verrechnet hat, zu denen Sie bestellt haben.
Wie Sie Parashift integrieren können
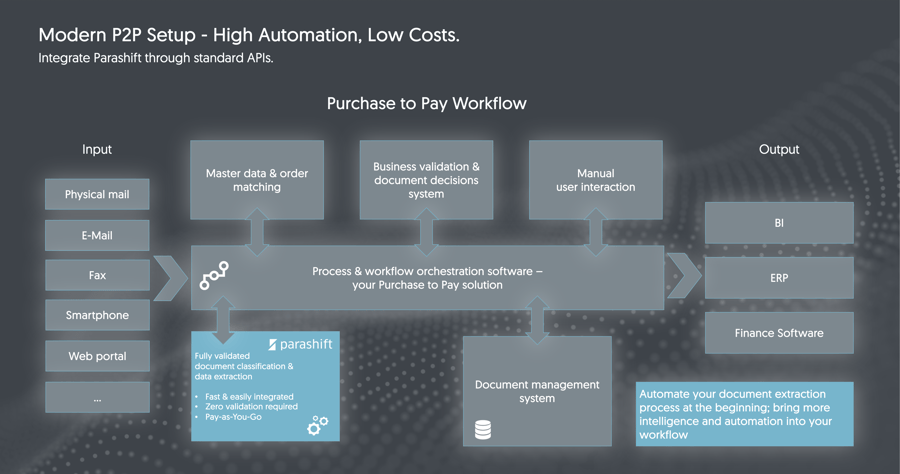
Die Integration von Parashift wird normalerweise nach am Anfang des Inputprozesses vorgenommen. Elektronische und physische Dokumente kommen über die verschiedenen Kanälen in ein führendes System – dies kann ein ERP-, Dokumentenmanagement-, Workflow-System oder sonstige Business Software sein, wo Sie Ihren Kreditorenworkflow oder P2P-Prozess abwickeln – und in diesem sitzen wir dann im Hintergrund beziehungsweise übernehmen die ganze Konvertierung hin zu einem strukturierten Format.
Mit der Grundlage dieser Metadaten können Sie dann wiederum in Ihrem führenden System
- ein Stammdatenmatching vornehmen
- Bestellabgleiche durchführen
- eigene Geschäftsregeln definieren
- Buchungsvorschläge erstellen
- oder aber auch spezielle Routings für Genehmigungsprozesse automatisieren.
In den meisten Fällen legen Sie das ursprünglich erhaltene Dokument noch in einem Dokumentenmanagement-System ab und haben dann lediglich die aufbereiteten Buchungsdaten, welche im ERP-System weiterverarbeitet werden. Sie sehen, wir sind lediglich ein kleiner aber entscheidender Teil in einem Gesamtprozess, der als Enabler für umfassendere Automation ins Spiel kommt.
Der Kostenpunkt
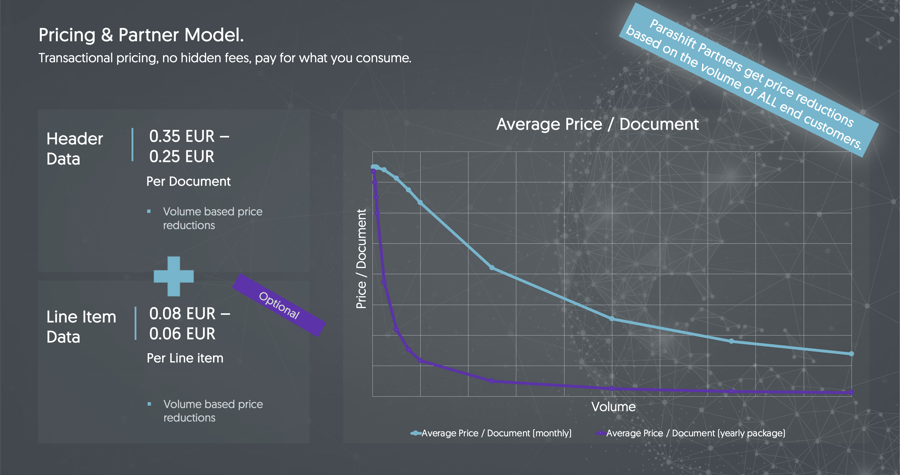
Kommen wir zu einem anderen spannenden Thema: dem Pricing. Wie schon angedeutet, verrechnen wir lediglich eine Transaktionsgebühr für die Anzahl verarbeiteter Dokumente. Verpflichtende laufende Fixkosten gibt es keine.
Ein voll validiertes Dokument inklusive Klassifikation und allen Kopfdaten kostet zwischen EUR 0.35 und EUR 0.25 (egal wie viele Seiten dieses hat), die optionale Extraktion der Positionsdaten zwischen EUR 0.08 bzw. EUR 0.06 pro Position.
Umso mehr Volumen Sie pro Monat mit uns verarbeiten, umso günstiger wird der durchschnittliche Preis pro Dokument. Für zusätzliche Kostenvorzüge bieten wir Ihnen ebenfalls optional die Möglichkeit Pakete zu kaufen, welche einen Rabatt auf das Volumen mehrerer Monate gewähren. Die Grösse dieser Pakete können Sie individuell bestimmen.
Die ersten Schritte
Wie gehts weiter? Wenn wir Sie überzeugen konnten, melden Sie sich doch bei uns, sodass wir entweder einen Produkt-Workshop oder einen Proof of Concept organisieren können. Alternativ können wir auch direkt ins Thema Integration und Produktionsbetrieb eintauchen.
Eine Kontaktaufnahme starten Sie am besten direkt hier, wo Sie gerne ein Meeting mit Thilo Rossa, unserem Head Product, buchen können. Sollten Sie noch keinen Testmandaten haben, registrieren Sie sich doch bei dieser Gelegenheit gleich über das untenstehende Banner und nutzen Sie die Chance, die Lösung 14 Tage kostenlos und unverbindlich zu testen.
