In this blog article, I want to provide an overview of what Parashift stands for as a company, what its document extraction solution capabilities are, and how it can be integrated. Last but not least, I will also go into pricing.
What can Parashift do for your Procure to Pay process?
With Parashift, we offer you an extraction solution that enables you to classify and extract data from over nine different Procure to Pay document types, such as invoices, offers, orders, delivery notes, etc. The data extracted from these documents is then delivered to your downstream processes in your ERP system, for example, or custom integrated into your web application.
In comparison to other solutions on the market, we not only classify the different documents and read out the most relevant fields based on the classification, such as the supplier, recipient, document date and number, amounts including partial amounts, tax and tax rate and item data, but we also manage the complete validation and correction process. This guarantees you the highest possible quality, and frees you from tiresome and costly data entry work. This enables robust automation process based on the initial document input.
Before I show you the platform, here is an overview to illustrate what we do in the background.
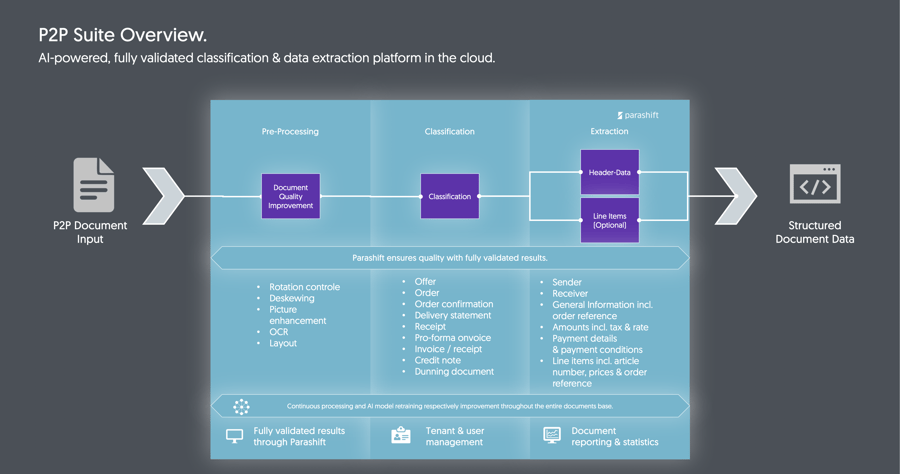
In normal production operation, you send various documents (we support multiple formats) via a REST API to the platform, where we perform pre-processing quality improvements. This means, for example, we do a rotation, should the document be upside down, we improve the quality of the image if necessary, and of course we do an OCR and layout creation. This is followed by classification, where we identify what type of document it is. Finally, we extract the most important data in order to create a uniform, structured data format from the unstructured documents, which can be transferred to any downstream systems.
In addition to header data, such as the address of the supplier and the recipient, reference numbers, delivery data, total amounts including tax rates and payment details, we also extract the individual line item data with all relevant data such as item description, item id (SKU or UPC), quantity, unit price and, of course, references of the items to orders and delivery notes, which are essential for compound entry and order reconciliation. At the end, you receive a structured JSON file back via our easy to implement REST API. Our standard SLA, which includes human validation, is typically three hours during business hours.
Solution benefits for Procure To Pay
In addition to the post-processing, which we do for you, we also offer:
- a solution that works out-of-the-box, without difficult template setup and configuration, and no training requirements.
- a quick & easy integration with your ERP, document management, workflow, ECM system or other business software using our REST API and optional webhooks.
- transparent transaction-based pricing – there are no costs other than the costs for processing your documents. So with us you also save high acquisition costs and all server, maintenance or support costs.
- with our cloud-based solution, you get top-notch intelligent data extraction software at a minimal cost. And that even includes post-processing validation of extraction results.
A glimpse into the user interface
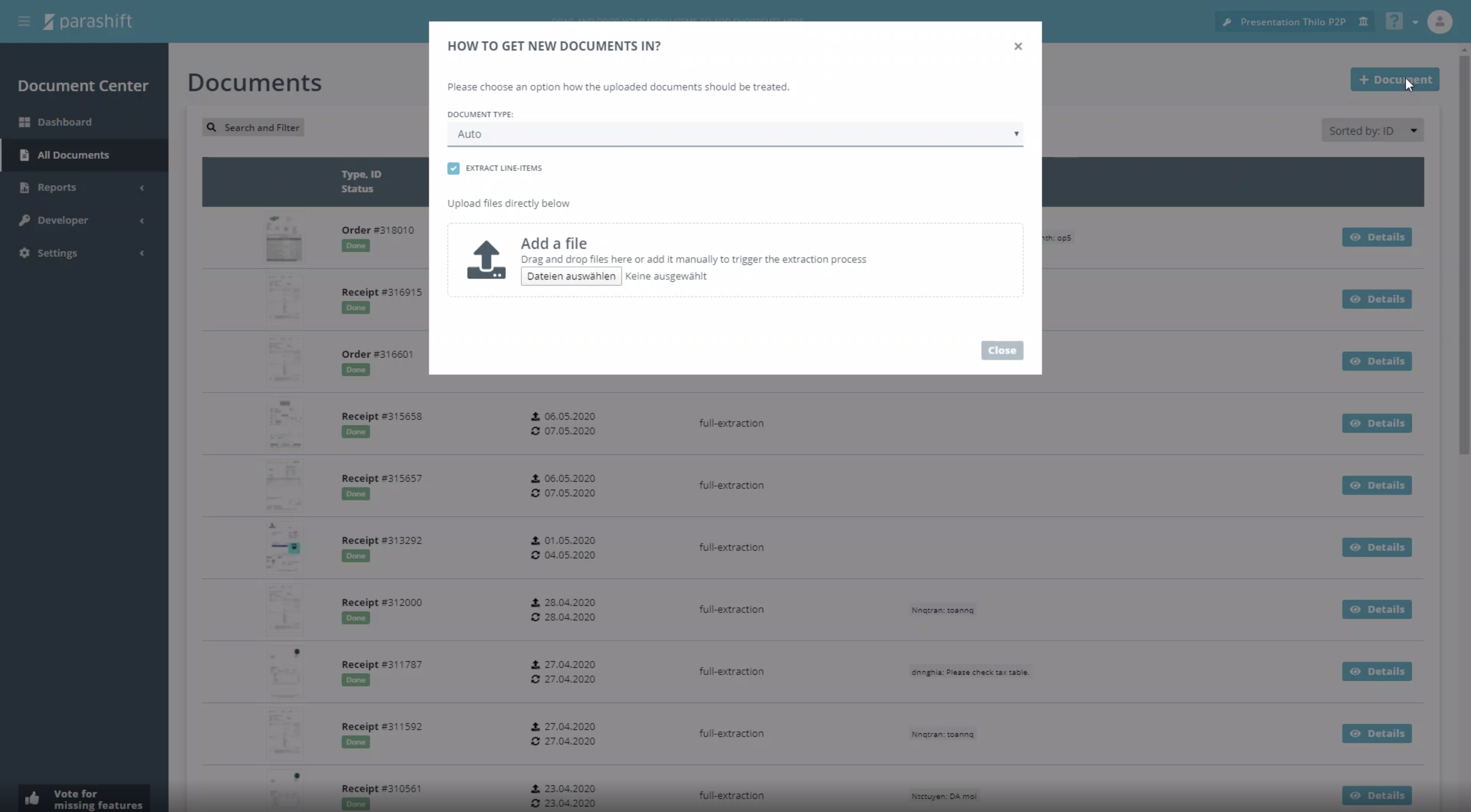
Now let’s take a look at the graphical user interface, which you would only need for non-standard use cases (for example, if you would like to validate the extracted fields yourself, or if you wish to manually upload documents). You can upload documents here, especially if you start a test run afterwards, by clicking the button in the upper right corner of the screen. When uploading via the dialog, which you can see here in the screenshot as a popup window, I can specify, like when uploading via our REST interface, whether line item data is to be extracted and whether the document is to be auto classified or if I want to specify a fixed document type myself. Afterwards, documents go into processing.
As already mentioned, we will deliver back completed and fully validated extraction results after three hours at the latest. In the background, our system goes over the document and interprets the relevant data to be extracted using machine learning on the basis of all documents we have processed in the past.
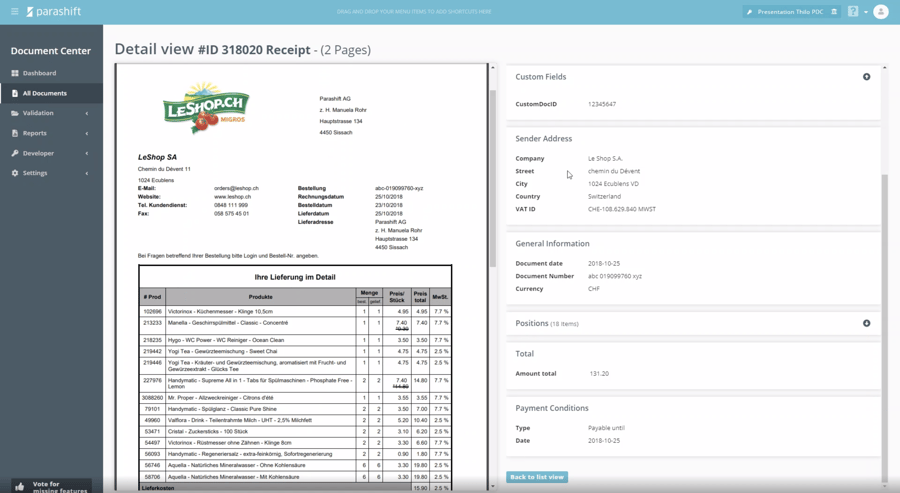
In this example of an invoice, we see that the supplier has been recognized, as well as various other header data: Invoice date, invoice number, currency, line items, as well as the total and the terms of payment. However, it is still possible that errors may have creeped in, or our algorithm did not return a high percentage of extraction certainty for some fields. That is just the nature of today’s world – no machine is capable of delivering flawless performance across all documents. At least not yet.
Nevertheless, by applying machine learning methodically in a new way and to an unprecedented extent to documents and thus benefiting from a “swarm learning” effect, we are step by step inching closer to our vision of fully autonomous document processing (i.e. perfect results without human interaction). We are therefore convinced that over time, we can take more and more human work out of the process and pass the cost savings on to our partners and clients.
Above you can see a post-processed version of the earlier uploaded invoice. This would be the kind of data quality you can expect from Parashift. Unlike before, we also have the invoice recipient here, who was not extracted by the engine. The service date was also added. The line item data has been broken down in more detail, as well as the total amount according to various tax rates and net and gross amounts.
Based on this metadata, you should therefore be able to post the invoice largely automatically. As an alternative, thanks to the line item data, you can reconcile the invoice directly with your internal purchase order and evaluate whether the vendor has actually invoiced on the terms and conditions on which you ordered.
Integration and Procure to Pay workflow
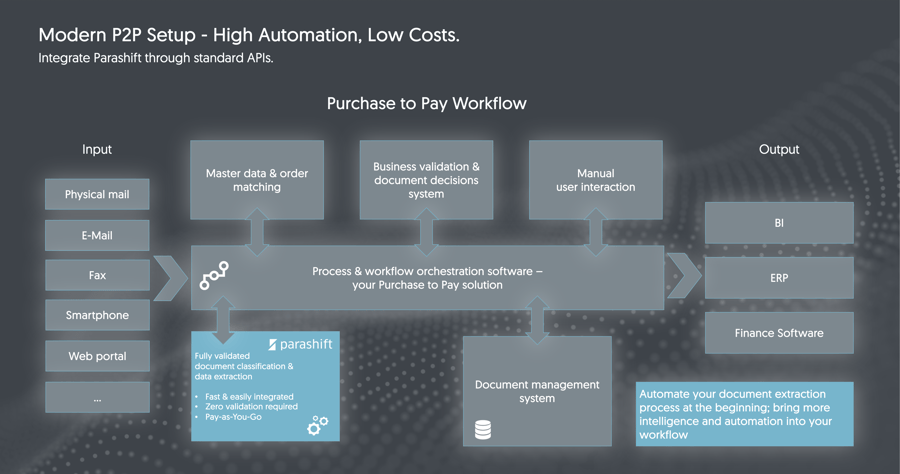
The integration of Parashift is normally done somewhere at the beginning of a given input process. Electronic and physical documents come through the various channels into a leading system – this can be an ERP, document management, workflow system or other business software where you run your accounts payable workflow or P2P process – and we sit in the background and respectively take care of the entire conversion to a structured format.
On the basis of this metadata, you can then do the following things in your leading system:
- carry out master data matchings
- perform order reconciliations
- define your own business rules
- create posting proposals
- or automate special routings for approval processes.
In most cases, you still store the document you originally received in a document management system and then only have the prepared posting data, which is processed further in the ERP system. As you can see, we are only a small but crucial part of the overall P2P process. In that sense, you can think of Parashift as an enabler for more comprehensive automation.
Pricing
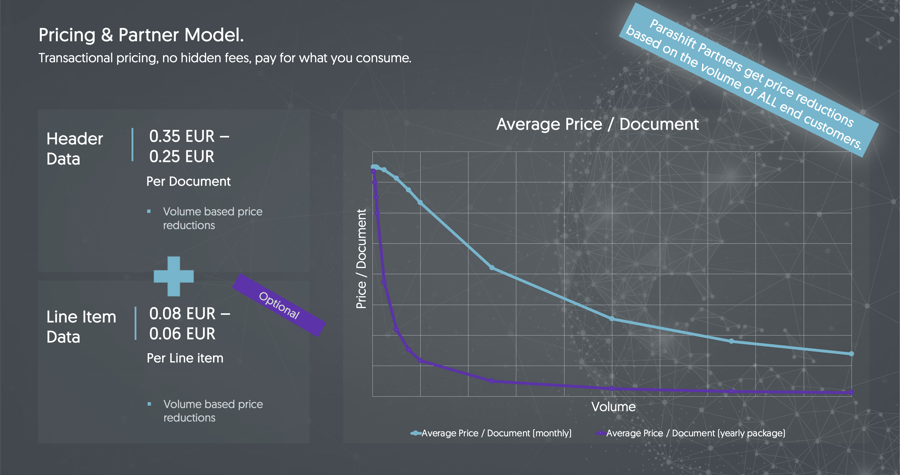
Let’s move on to another topic of interest: pricing. As already indicated, we only charge a transaction fee for the number of documents processed. There are no recurring fixed costs.
A fully validated document including classification and all header data costs between $0.25 and $0.35 (irrespective of the number of pages), and the optional extraction of line item data between $0.06 or $0.08 per item.
The more volume you process with us per month, the lower the average price per document. For additional cost savings, we also offer you the option of purchasing packages that grant a discount on the volume of several months. You can of course determine the size of these packages individually.
Next steps
What’s next? If we have convinced you, please feel free to contact us so that we can set up a product demo or proof of concept. Alternatively, we can dive directly into the topic of integration and the go to market plan.
The best way to contact us is to start directly here, where you can book a meeting with Thilo Rossa, our Head of Business Development. If you don’t have a test mandate yet, please take this opportunity to register by clicking on the banner below and take advantage of the opportunity to test the solution for 14 days free of charge and without any obligation.