Employees of all types of organizations deal with documents and text data on a daily basis. The most common types are pdf documents such as correspondence, invoices, purchase orders, etc. However, many organizations still have to deal with paper-based and hand-filled documents such as receipts, forms, handwritten receipts and the like. They not only need to extract information from these documents, but also prepare them for the processes that follow. Mechanical techniques are therefore indispensable for capturing such documents. The costs are simply too high for purely manual capture. In addition, companies receive documents via different channels. Therefore, a fast setup is needed where documents can be quickly and cost-effectively captured in machine-readable form and immediately forwarded to the right place.
Through which channels do companies receive data?
Many companies work with documents that are uploaded by their customers in the form of image files via company-owned portals. These can be, for example, proof of identification, confirmation of residence, tax receipts, pay slips, etc. Instead of manually searching in these documents for the required information such as name, date of birth, salary and tax amounts, it makes sense to use modern OCR software that takes over these documents immediately after upload, analyzes them and can extract the required field values in no time at all, which can then be transferred to the leading systems such as an ERP or DMS system.
Another source of documents is, of course, today’s e-mails. Because very often these contain attachments with pdf documents or images that contain relevant information and need to be processed further. And although the world is becoming increasingly digital, we still have a lot of paperwork that is sent back and forth. Believe it or not, but almost half of all invoices are still sent by fax and take a week or more to process. Crazy, right?!
Below you will find an illustrative overview of other sources where companies get documents from.
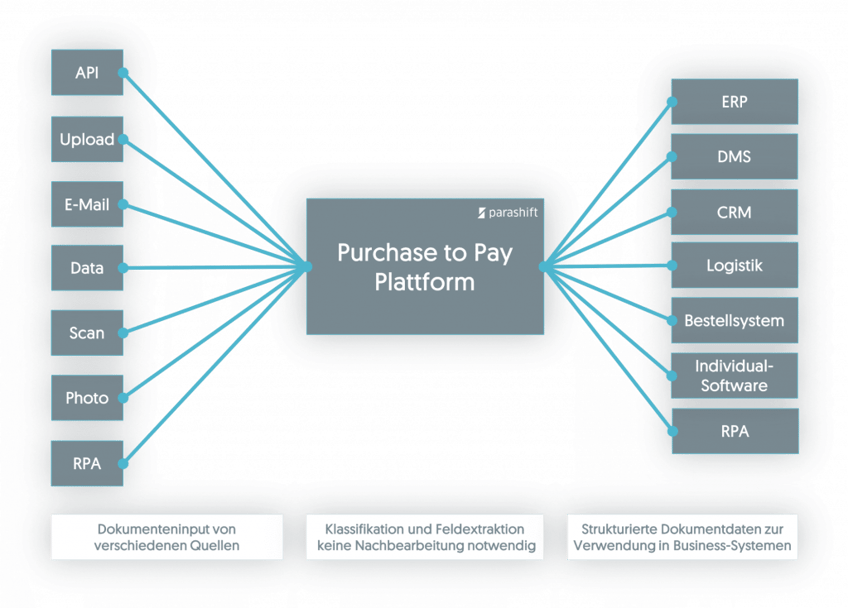
As mentioned at the beginning, a cost-effective and fast process design of document-heavy processes requires a specific setup that can pick up and process documents decentrally and distribute them company-wide to the right departments and employees. Cloud-based multi-channel document processing software can meet these requirements.
The implementation of such an extraction system can prove to be a key differentiator between a good company and a top company.
Why AI OCR software makes everyday business life easier
Thanks to modern machine learning and deep learning technologies and advanced architectures, AI-based Cloud-OCR software is now able to read all kinds of information from documents, no matter how unstructured, and to provide it in a structured way. Even handwritten texts can be processed relatively robustly. The data extracted and possibly subsequently validated in this way can then be fed into a central document management system or ERP or CRM software, for example. The fact that such systems can learn from experience and annotations means that, over time, less and less human interaction is required, which will result in further significant cost savings for you as a client.
What advantages cloud infrastructure can offer for OCR
Decentralized and different data sources, real-time processing and cost-effective, high-performance OCR data extraction are exactly the dimensions that can be covered by processing documents on a cloud-based platform. The cloud infrastructure enables your documents to be processed automatically as soon as they are received. No matter how many documents you upload. In contrast to locally operated OCR, any volume of documents can be extracted in real time and thus offers an optimal solution for the efficient capture and provision of data for downstream processes. In addition, you also address the susceptibility to errors that arise from manual processing.
Such cloud-hosted multi-channel document processing systems are also very easy to integrate via API into other systems where the information is further processed. In this way, you can make business processes more fluid and ensure further efficiency gains through cross-system process automation and interface reduction.
In summary, it can be said that both paper and electronic documents are rich sources of information which, if made inexpensive and quickly reusable, can bring a lot of value. In this respect, multi-channel document processing systems have the ability to classify documents directly and automatically, to understand the type of information they contain, to extract this information in a structured way and to pass it on to connected systems so that it can be further used by clerks, data managers, analysts and other employees.
If you need to obtain data from various sources yourself and would like to automate these processes, feel free to register for a 14-day test account via the banner below and test document AI for yourself.
Please note: The current software version only supports the extraction of documents relevant to the purchasing process without configuration.
