Countless documents such as orders, delivery notes and invoices are issued on a daily basis. These documents must then be captured in corporate IT systems in some way. Nowadays, technological developments have led to efficient methods of passing these documents on to downstream processes in a machine-readable and structured form. At Parashift, we mainly use machine learning for this purpose. Because this type of technology allows us to reduce the necessary human intervention to a minimum. This offers numerous advantages. Not only does it save time and money, but it can also avoid rather monotonous and tedious tasks. As you can certainly imagine, not so long ago, document capture looked quite different. From the first inventions to the latest developments, the following article is intended to give you an impression of how modern document processing has developed over the years.

Beginnings and first attempts
Scientists have always dreamed of using machines to replicate human capabilities. This includes reading and categorizing what is read. The origins of optical character recognition (OCR) date back to 1870, when Charles R. Carey, an American inventor, invented the retina scanner – an image transfer system that uses a mosaic of photocells. Two decades later, the development of a successive image scanner by the German inventor Paul Nipkow gave the decisive impetus for today’s televisions or reading machines and thus for character recognition.
However, the first OCR devices were primarily intended for blind and visually impaired people, such as the optophone developed in 1912 by the Irish inventor Dr. Edmund Fournier d’Albe. The optophone was a scanner that, when moved across a printed page, produced sounds that correspond to certain letters or characters so that they can be interpreted by a blind person.
It was not until the 1950s and the invention of the Optacon that the potential applications that OCR can have in the business world were recognized. From that time on, the focus of development was also on the possible applications of OCR for businesses.
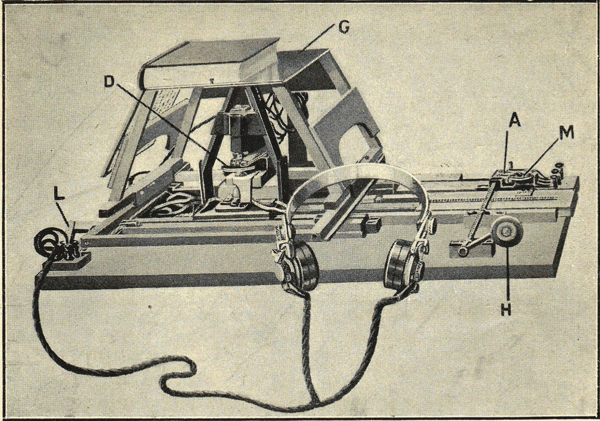
The first OCR devices
In 1950, the technological revolution was advancing at a rapid pace, resulting in increasing data volumes and thus making electronic data processing increasingly important. At that time, data was still entered by punch cards and initially processed by hand. However, the processing of increasing amounts of data required a cost-effective alternative to manual processing. At the same time, machine reading technology became sufficiently mature for commercial applications. As a result, OCR machines went into mass production in the mid-1950s.
The first real OCR machine was installed in 1954 at the American magazine Reader’s Digest. This device was used to convert typewritten sales reports into punch cards that could be read and searched by computers. It was not yet possible to extract only the most relevant data, so the entire documents were read in. Moreover, the devices were still quite bulky and expensive.

Commercialization and first automation
The commercial OCR systems that appeared between 1960 and 1965 can be described as the first generation of OCR. This generation made it possible to automate the first few steps in the process of document processing. However, the first devices still had a very limited number of symbols and letters that could be read. And since the symbols were specially designed for machine reading, the first symbols did not look very natural either.
With the further development of the devices, the first multifont devices appeared, which could read up to ten different fonts. The IBM 1418 Optical Character Reader is a representative model for this generation. These devices worked with so-called template matching, which made the above-mentioned automation possible. The OCR devices could now be trained to read only predefined sections of documents. This meant that a large amount of work that previously had to be done by humans cloud now be taken over by the OCR devices.
In the mid-1960s and early 1970s, the second generation of OCR machines appeared. These systems were capable of recognizing normal, machine-printed characters and also had the ability to recognize handwritten characters. However, the character set for handwritten characters was limited to numbers and a few letters and symbols.
The famous and also first system of this kind was the IBM 1287, which was presented at the 1965 World Fair in New York. Further technological advances were observed at Toshiba, who at the same time launched the first automatic letter sorting machine for postal codes. Also in the same period, Hitachi succeeded for the first time in producing a high performance OCR machine at low cost.
Another milestone was the progress made in standardization. For example, the first optically machine-readable font “OCR-A” was developed in 1968 by Adrian Frutiger from Switzerland. This font was highly stylized and designed to facilitate optical recognition, but still remained legible for humans. A few years later, Frutiger designed a new typeface, “OCR-B”, which replaced its predecessor. The reason for the new typeface was its low popularity in Europe and the technological advances made in optical character recognition in the meantime. Compared to OCR-A, this typeface therefore resembles a normal, sans-serif print font much more. It was then declared a worldwide standard in 1973 by the International Organization for Standardization, or ISO in short. Some attempts were made to merge the two fonts into one standard, but instead devices were developed that could read both standards.

Technological progress and the Kurzweil Reading Machine
For the 3rd generation of OCR systems, which came onto the market in the mid-1970s, the greatest challenge was the recognition of documents with poor quality and large printed and handwritten character sets.
Significant advances in hardware technology have resulted in lower costs and improved performance of the devices. Although more and more sophisticated OCR machines came onto the market, simple OCR machines were still widely used. In the time before personal computers (PCs) and laser printers began to dominate the field of text production, typing was a special niche for OCR. The uniform printing distance and the small number of fonts made simple OCR devices very useful. Rough drafts could be created on ordinary typewriters and fed into the computer via an OCR device for final processing. In this way, word processing programs, which were a costly resource at the time, could be used by several people, thus avoiding high acquisition costs.
At that time, researcher Raymond Kurzweil succeeded in launching the first commercial reading machine capable of translating printed matter into spoken words: The Kurzweil Reading Machine. A milestone in history. For the first time there was a commercial solution that allowed blind people to read.

Distinction between OCR engine and OCR software
By the way, there is very important distinction when we talk about OCR. This is because the technology that performs the actual identification of the characters and delivers back the coordinates of the values found, namely the OCR engine, should not be confused with the technology that divides the images or documents into layouts, bundles the contents, interprets them and returns them in a structured form. Although there are also some engines that form letters, spaces, numbers and symbols into blocks, this is normally part of the OCR software. This is also the case at Parashift. The engines we use focus only on text recognition. Usually, the first thing we do is to find lines, which are then broken down into individual words or characters. Some of the engines use dictionaries to improve the quality. Everything that follows the parsing of the text falls under the scope of the OCR software. But now back to the historical part of this article…
OCR software and machine learning-based OCR
Although OCR devices became commercially available in the 1950s, only a few thousand systems had been sold worldwide by 1986. The main reason for this was the cost of the devices. However, as hardware became cheaper and OCR systems became available as software packages, sales figures also increased significantly.
Advances in computer technology have made it possible to integrate the recognition part of OCR into software packages that work on PCs. However, OCR software also had disadvantages, particularly in terms of speed and the type of character sets read. Today, several thousand OCR systems are sold every week. In addition, the cost of Omnifont OCR devices has been falling year after year, which has led to OCR devices finding their way into the mainstream.
A few years ago, the first attempts to combine OCR with machine learning were made. In 2013 the famous MNIST (Modified National Institute of Standards and Technology database) was established. This database consists of handwritten letters and numbers and is used for machine learning training. With this, document capture has made the step into the latest digital revolution and the focus has been on complete automation since then. And researchers are registering quite promising successes here, although it must also be clearly emphasized that we are only at the beginning and that there are still numerous technical challenges to be mastered.
Template-based OCR vs. machine learning-based OCR
Although template-based OCR is much older than machine learning-based OCR, the results of template recognition are usually quite good and consistent, which means that much of the manual work can be automated. However, automation also requires a lot of prior configuration for each field to be extracted. Defining in advance the exact location on the document where the information is to be found and how it is to be extracted is crucial. In contrast to the complete automation that is possible with machine learning-based OCR, this can therefore be a major and very costly disadvantage.
Another major disadvantage of template-based OCR, as already mentioned, is that document structures that deviate from the template do not work. In other words, as soon as the document changes, even minor layout changes, the machine must be reconfigured, which is extremely time-consuming. In addition, the setup of the templates is not quite simple either and usually requires external experts. Therefore, the successful management of templates can quickly become very cost-intensive and a major challenge.
Machine learning-based OCR systems offer a solution to these problems. The machine learning algorithms are trained with the help of training sets, i.e. data sets for training purposes. A validation set is then used to optimize the resulting model structures and, if necessary, adjust some design parameters. Finally, a test set is used to measure the performance of the algorithms and to check their suitability for generalization. In doing so, for example, the accuracy, sensitivity or speed of the generated system is checked. If the results are not satisfactory, the algorithms must be further optimized with new training sets.
Due to the way the algorithms of machine learning-based OCR solutions work, there are significant advantages over template-based OCR solutions. They differ in the way that they offer more flexibility and do not require templates. This means that your company no longer needs to carry out activities such as maintenance, consulting and coordination with regard to templates, which means significantly lower costs for you. By continuously training the algorithms on all customer documents, performance is also continuously improved, which in turn leads to less human intervention and lower costs over time. And you don’t have separate large-scale projects for extraction rate improvements, which quickly generate exponentially higher costs with increasing extraction quality.
Machine learning-based OCR solutions therefore offer numerous advantages over template-based OCR solutions. Nevertheless, it should be noted once again that the template approach can be very accurate. But as soon as different layouts and document changes come into play, machine learning-based OCR solutions are the clear winners.
Test now!
Convince yourself of the potential of machine learning-driven OCR and upload various test documents (ATTENTION: currently, we only process documents from purchasing: offer, order, order confirmation, delivery note, pro-forma invoice, invoice, receipt, credit note and dunning letter).
PS. By the way, on working days between 08:00 and 17:00 CET, we also validate the extraction results within 3 hours. So with Parashift you get outstanding data quality and do not need to tie up resources unnecessarily for tasks that are not directly part of your core business.
